適學人群
-

擁有多年從業經驗的大數據從業者
渴望突破自我職業瓶頸,轉型推薦系統工作 -

具有數學學習背景的高校畢業生
希望可以從實際項目中理解推薦系統
提升工作經驗
擁有多年從業經驗的大數據從業者
渴望突破自我職業瓶頸,轉型推薦系統工作
具有數學學習背景的高校畢業生
希望可以從實際項目中理解推薦系統
提升工作經驗
系統性梳理整合大數據技術知識與機器學習相關知識
深入了解推薦系統在電商企業中的實際應用
深入學習并掌握多種推薦算法
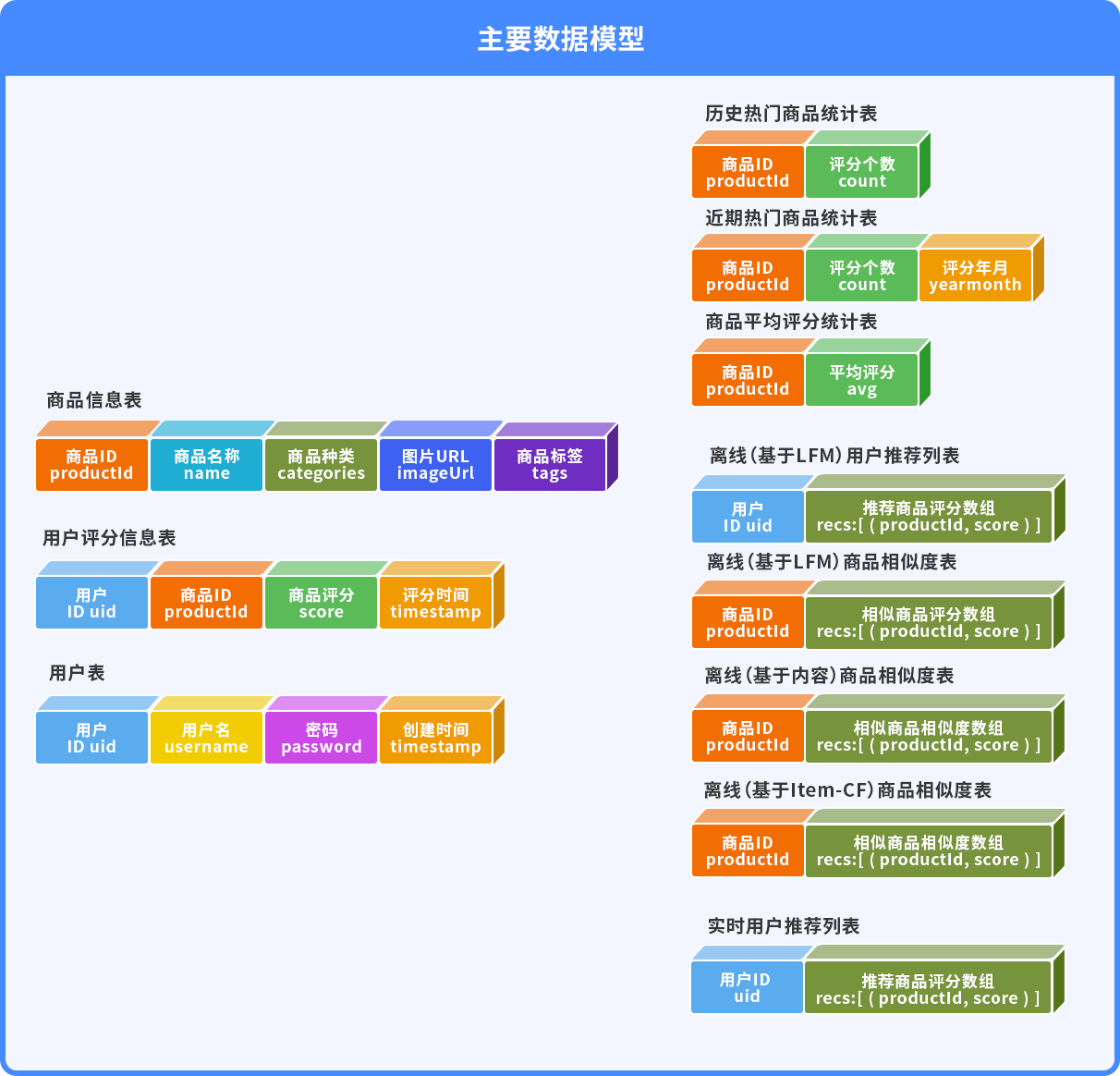
基于統計的離線推薦基于隱語義模型的離線推薦基于自定義模型的實時推薦基于Item-CF的離線相似推薦

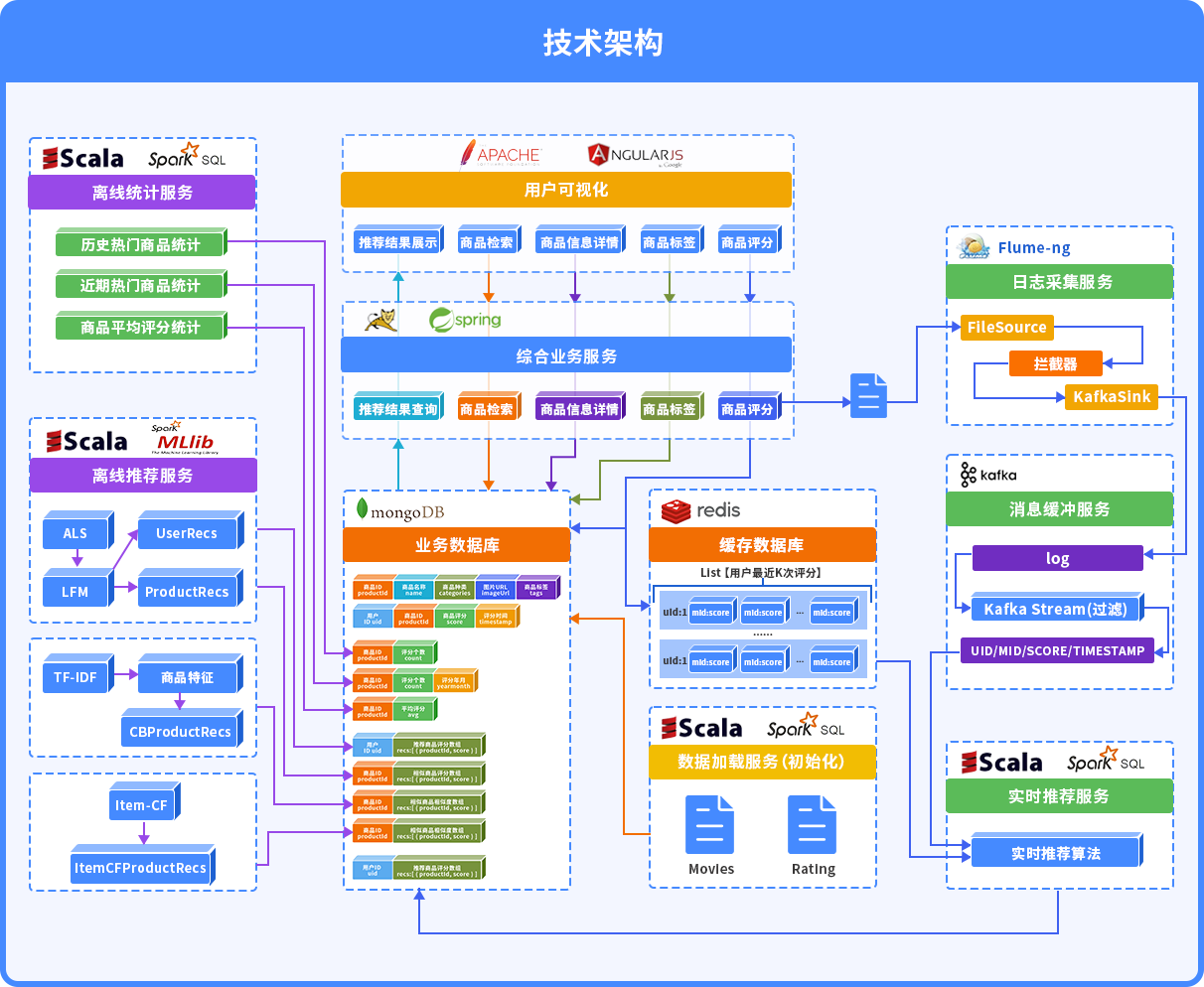
使用Flume、Kafka搭建實時數據采集系統,對多樣化的用戶行為數據和大體量的業務數據進行采集清洗和系統調優;

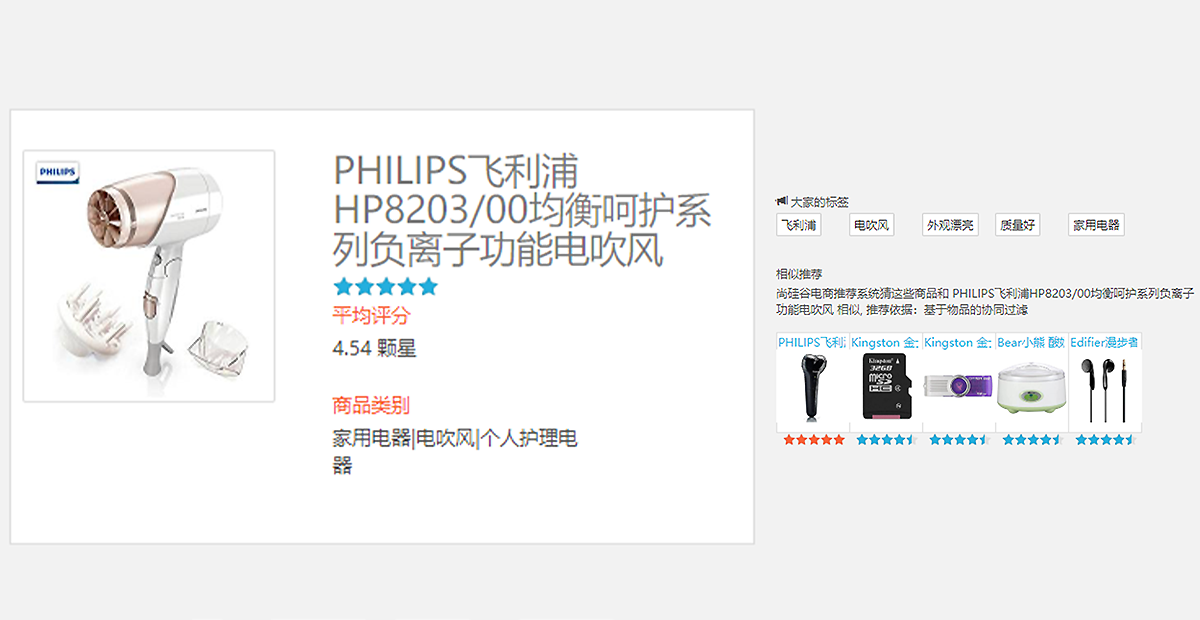
使用ALS算法對評分矩陣做矩陣分解,根據商品的隱語義特征計算商品之間的相似度,并將相似度做倒排索引,并將倒排數據持久化到MongoDB;

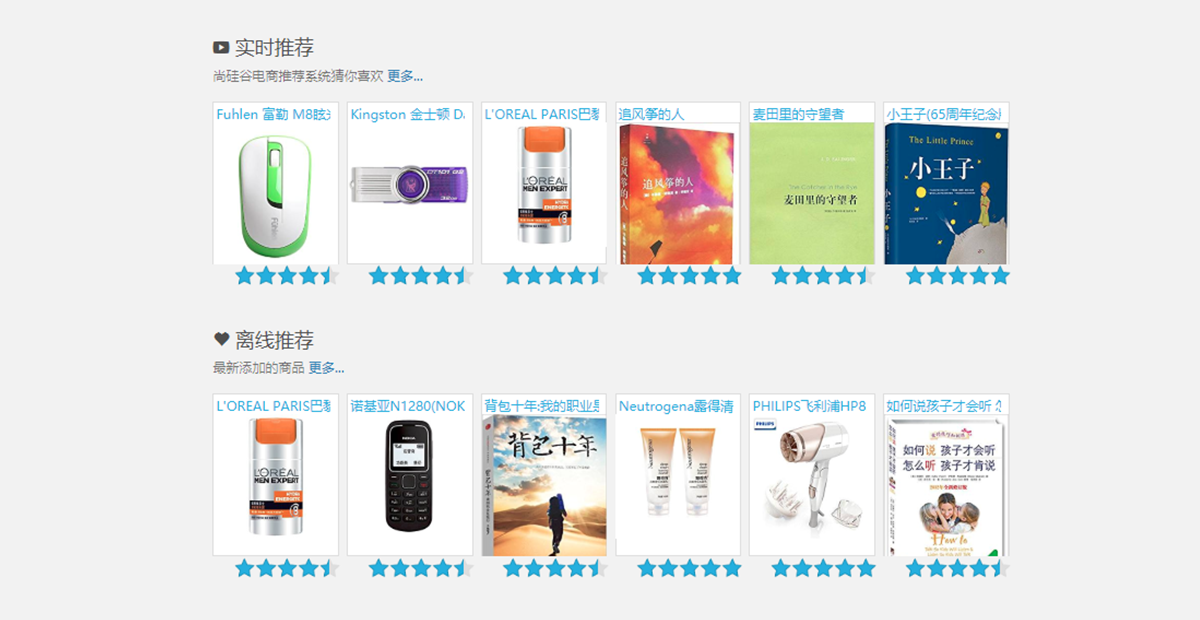
實時推薦:利用商品的相似度倒排,根據用戶商品評分或者點擊行為來做推薦,使用Spark Streaming來實時計算推薦優先級,然后存儲到Redis中,提高用戶的訪問體驗;

利用商品的標簽數據,使用TF/IDF來計算商品之間的相似度,同樣使用倒排的思路持久化道MongoDB;

使用Spark計算每個門類的平均評分商品來解決冷啟動問題;

使用Spark將日志數據做分析和處理,然后持久化到MongoDB、ES等數據庫中,實現data loader功能;

通過A/B測試來評估推薦結果;

優化Spark的計算效率,比如將一些數據進行.cache()操作緩存,對某些數據做broadcast廣播到其他節點,加快運算;

使用Git進行版本管理,遠程代碼倉庫使用自己搭建的gitlab;

將推薦系統引擎模塊化:als矩陣分解的相似度計算、基于tfidf的相似度計算、實時推薦模塊,每一個引擎都會產生一個推薦列表,對不同的引擎賦予不同的權重,然后合并列表,產生推薦數據。